The scan package (sofia_redux.scan) package implements
an iterative map reconstruction algorithm, for reducing continuously
scanned observations. It is implemented in pure Python, with numba
just-in-time (JIT) compilation support for heavy numerical processes,
and multiprocessing support for parallelizable loops.
Main Classes¶
The primary data structures for modeling an instrument in the scan package are listed below, and their relationships are diagrammed in Fig. 131.
ChannelData: an class representing a set of detector channel (pixels). A channel has properties, such as gains, flags, and weights etc.
ChannelGroup: A generic grouping of detector channels. This is implemented as a wrapper around the ChannelData class, with access to specific channel indices held by the underlying arrays.
Channels: An class representing all the available channels for an instrument.
Frames: A data structure that represents the readout values of all Channels at a given time sample, together with software flags, and associated properties (e.g. gain, transmission, weight etc.)
Integration: A collection of Frames that comprises a contiguous dataset, for which one can assume overall stability of gains and noise properties. Typically an Integration is a few minutes of data.
Scan: A collection of Integrations that comprise a single file or observing entity. For HAWC+, a scan is a data file, and by default each scan contains just one integration. However, it is possible to break Scans into multiple Integrations, if desired.
Signal: An object representing some time-variant scalar signal that may (or may not) produce a response in the detector channels. For example, the chopper motion in the ‘x’ direction is such a Signal (available as ‘chopper-x’) that may be used during the reduction.
Dependents: An object that keeps track of the number of model parameters derived from each Frame and each Channel. It measures the lost degrees of freedom due to modeling (and filtering) of the raw signals, and it is critical for calculating proper noise weights that remain stable in a iterated framework. Failure to count Dependents correctly and accurately can result in divergent weighting, which in turn manifests in over-flagging and/or severe mapping artifacts. Every modeling step keeps track of its own dependents this way in the analysis.
ChannelDivision: A collection of ChannelGroups according to some grouping principle. For example, the channels that are read out through a particular SQUID multiplexer (MUX) comprise a ChannelGroup for that particular SQUID. The collection of MUX groups over all the SQUID MUXes constitute a ChannelDivision.
Mode: An object that represents how a ChannelGroup responds to a Signal.
Modality: A collection of Modes of a common type. Just as Modes are inherently linked to a ChannelGroup, Modalities are linked to ChannelDivisions.
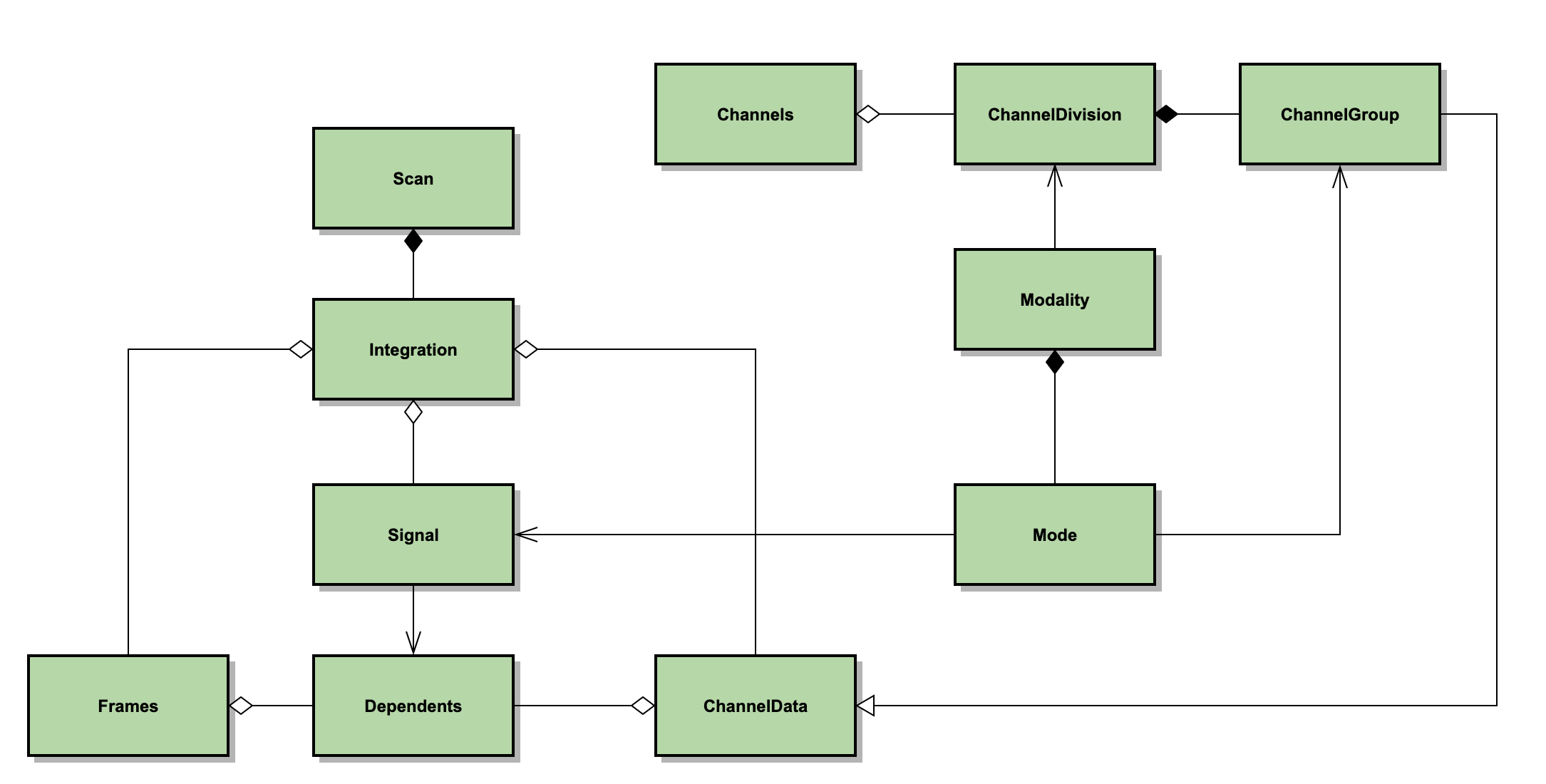
Fig. 131 Principal scan data classes. Channels has a set of ChannelDivisions. ChannelDivision is composed of ChannelGroups, which inherit from ChannelData. Modality depends on ChannelDivision and is composed of Modes. Mode depends on ChannelGroup and depends on Signal. Scan is composed of Integrations. Integration has a collection of Frames, Signals, and ChannelData. Frame and ChannelData have a collection of Dependents; Signal depends on Dependents.¶
For example, the HAWC instrument is modeled as a set of Channels, i.e. pixels, for which each has a row and a column index within a subarray. The raw timestream of data from the channels is modeled as a set of Frames, contained within an Integration. To decorrelate the rows of the HAWC detector, a Modality is created from “rows” ChannelDivision. This modality contains Modes generated for each ChannelGroup with a particular row index (row=0, row=1, etc.). Each mode is associated with a Signal, which contains the correlated signals for the row, determines and updates gain increments, subtracts them from the time samples in the Frames, and updates the dependents associated with the Frames and ChannelData.
The reduction process is run from the class Reduction, which performs the reduction in a Pipeline instance, and produces a SourceModel (see Fig. 132). A Reduction may create a set of sub-reductions to run in parallel, for processing a group of separate but associated source models. These sub-reductions are used, for example, to process HAWC+ R and T subarrays separately for Scan-Pol data.
Each Pipeline is in charge of reducing a group of Scans mostly independently (apart from resulting in a combined SourceModel). The Pipeline iteratively reduces each Scan by repeatedly executing a set of tasks, defined by a Configuration class. Metadata for the observation, including the Configuration and instrument information, is managed by an Info class associated with the Reduction.
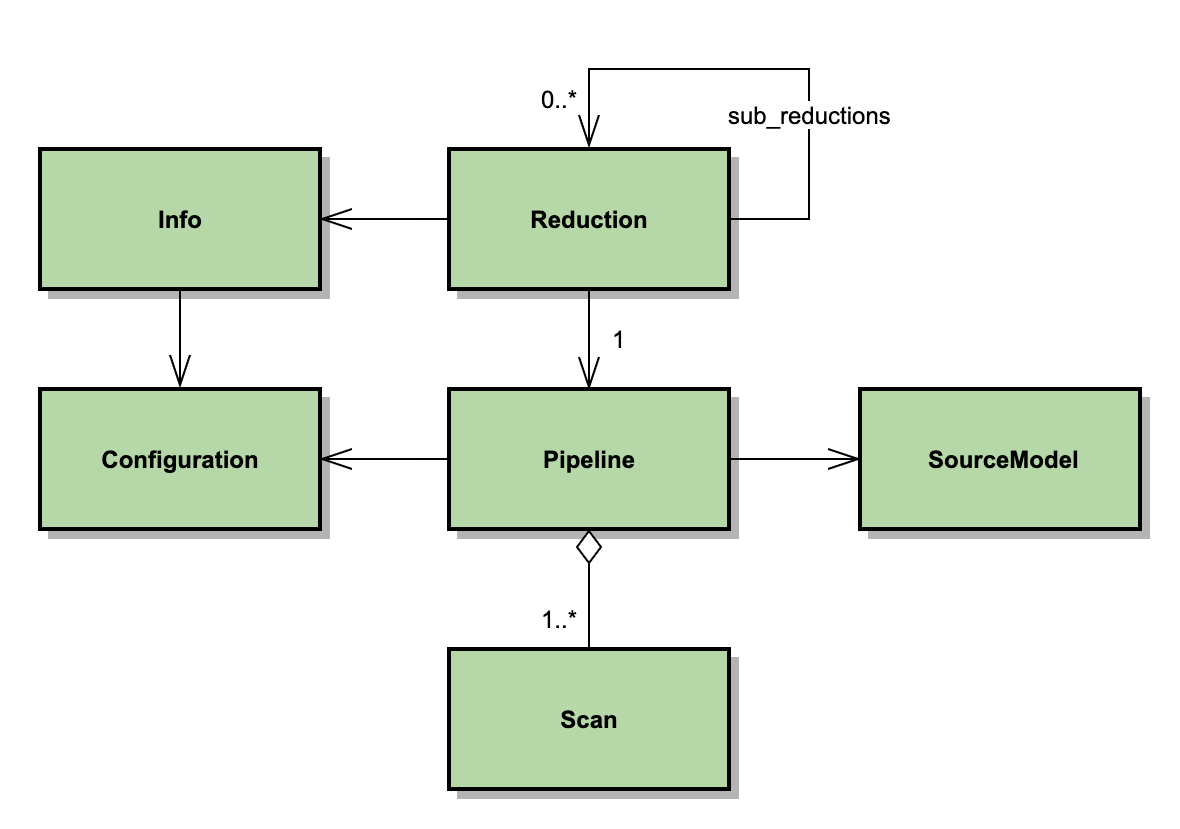
Fig. 132 Principal scan processing classes. A Reduction creates a Pipeline or, optionally, sub-reductions that create their own Pipelines. The Reduction depends on Info, which contains a Configuration. Pipeline depends on Configuration and on SourceModel, and has an aggregation of Scans to reduce.¶
Top-Level Call Sequence¶
The symbol \(\circlearrowright\) indicates a loop, \(\pitchfork\) (fork) indicates a parallel processing fork, square brackets are methods that are called optionally (based on the current configuration settings). Only the most relevant calls are shown. Ellipses (…) are used to indicate that the call sequence may contain additional elements not explicitly listed here and/or added by the particular subclass implementations.
Call sequence from sofia_redux.scan.reduction.Reduction:
Reduction.__init__()
Info.instance_from_intrument_name()
Info.read_configuration()
Info.get_channels_instance()
Reduction.run()
Info.split_reduction()
\(\pitchfork\) Channels.read_scan()
Channels.get_scan_instance()
Scan.read(filename: str)
Scan.validate()
\(\circlearrowright\) Integration.validate() …
Frames.validate() …
\([\) Integration.fill_gaps() \(]\)
\([\) Integration.notch_filter() \(]\)
\([\) Integration.detect_chopper() \(]\)
\([\) Integration.select_frames() \(]\)
\([\) Integration.velocity_clip() / acceleration_clip() \(]\)
\([\) KillFilter.apply() \(]\)
\([\) Integration.check_range() \(]\)
\([\) Integration.downsample() \(]\)
Integration.trim()
Integration.detector_stage()
\([\) Integration.set_tau() \(]\)
\([\) Integration.set_scaling() \(]\)
\([\) Integration.slim() \(]\)
Channels.slim()
Frames.slim()
\([\) \(\circlearrowright\) Frame.jackknife() \(]\)
Integration.bootstrap_weights()
Channels.calculate_overlaps()
Reduction.validate()
Info.validate_scans()
Reduction.init_source_model()
Reduction.init_pipelines()
\(\pitchfork\) Reduction.reduce()
\(\circlearrowright\) Reduction.iterate()
Pipeline.set_ordering()
\(\pitchfork\) Pipeline.iterate()
\(\circlearrowright\) Scan.perform(task: str)
\(\circlearrowright\) Integration.perform(task: str)
\([\) Integration.dejump() \(]\)
\([\) Integration.remove_offsets() \(]\)
\([\) Integration.remove_drifts() \(]\)
\([\) Integration.decorrelate(modality, …) \(]\)
\([\) Integration.get_channel_weights() \(]\)
\([\) Integration.get_time_weights() \(]\)
\([\) Integration.despike() \(]\)
\([\) Integration.filter.apply() \(]\)
\(\circlearrowright\) Pipeline.update_source(Scan)
SourceModel.renew()
\(\circlearrowright\) SourceModel.add_integration(Integration)
SourceModel.process_scan(Scan) …
SourceModel.add_model(SourceModel)
SourceModel.post_process_scan(Scan)
\([\) Reduction.write_products() \(]\)
Most of the number crunching happens under the Integration.perform call, highlighted in bold-face. It is a switch method that will make the relevant processing calls, in the sequence defined by the current pipeline configuration.